

Before writing Master Ruby Web APIs, I was kind of a REST fanatic. I thought it was the holy grail, the secret sauce defined years ago (before the Web was cool) that would allow people to write awesome web APIs.
Oh boy, what a disappointment.
The usual origin story
I started like everyone else, learning that a properly built web API needed to offer nice looking resources (/users), handling the various HTTP verbs (get, post, etc.) which are semantically loaded with rules and behaviors defined in RFCs. I learned those approaches that by working on Ruby on Rails applications. All was well for a while, and I spent a few years building apps that way.
I never took the time to dig deeper into Roy Fielding’s dissertation or learn more about REST, I thought I was building RESTful APIs. I never actually wondered why people didn’t call them “REST APIs”, was there REST-half APIs or partially-REST ones? ¯_(ツ)_/¯
By that point, I had spent the past two years building web APIs in Ruby and had seen all kinds of APIs. I felt I knew the right way to build RESTful APIs. I also wanted to write another programming book, so I naturally thought I had to share my knowledge.
Writing Master Ruby Web APIs
The first thing I did, before writing a single line of text or code for MRWA, was research. I went through a lot of content, starting with RESTful Web APIs as I thought it would give me a great understanding of REST and what is a RESTful Web API. Well, it left me disappointed and wanting for more. There was so many mentions of the “Semantic Gap” that I felt most of the book was written from a theoretical perspective, so barely anything I could use in practice, for the book or my apps.
The Semantic Gap is the difference in understanding of web applications by humans and by programmed clients. We, as humans, are able to open the homepage of a website, discover linked pages and navigate around. The applications we build aren’t that smart, unfortunately, we need to tell them what to do. That’s why human-readable documentation is necessary for web APIs today, because humans need to read through them and implement their apps in the right way.
The current approach offered by REST is to basically try to bridge the gap as much as possible, until it is closed. Unfortunately, I don’t think we’re getting there in the coming years.
This realization was like a cold shower. I decided to focus more on building HTTP APIs, and the first step was dedicated a whole module to review the basics of building stuff for the Web. That meant reviewing and putting in practice all the features that came with HTTP (if they made sense in the context of an API), without worrying too much about all the REST side of things.
In the second module of the book, I teach how to build a complex Ruby on Rails web API by going up to level 2 in the Richardson’s Maturity Model. I felt that was enough since that’s what most businesses are doing today, and I wanted to teach something practical.
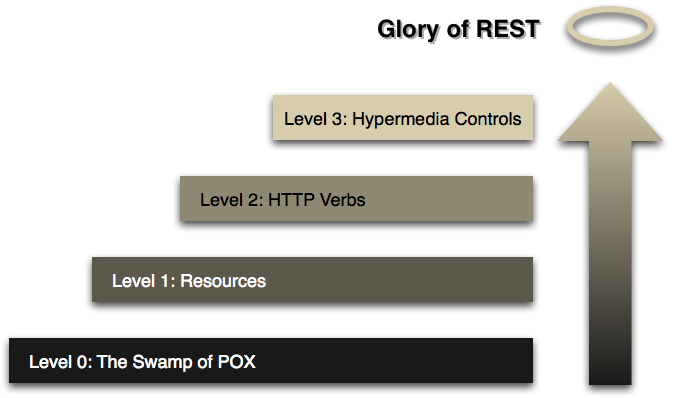
Picture from this post: Richardson Maturity Model
Getting frustrated
Finally, the last module was supposed to focus on HATEOAS. I tried, I really did. But I realized it wasn’t really practical. Sure, I could use hypermedia links to notify a client that an endpoint had moved (as long as the client had a way of handling this safely, as in don’t follow redirections forever or get stuck in a loop), but I still needed to hardcode how and where to interact with the API.
There were some interesting specifications though, like the Hydra spec. With it, if I was building a client to show data in the way the API was built, I could just build screens dynamically based on the returned data (unfortunately, I wouldn’t be able to customize each screen to offer a better UX to the users). While the idea sounds good in theory, it has little practical value for our needs today.
In the end, I feel building clean HTTP APIs is all about embracing good ol’ software engineering concepts and keeping your users happy.
Chilling out
These days, I’m not really worrying about building RESTful APIs anymore. I don’t really use the word anymore. At OmiseGO, we decided to not bind our APIs to HTTP, and went down the JSON-RPC road, with full custom error codes, etc. We wanted to stay “communication protocol”-agnostic to offer the same kind of responses through HTTP, Websockets, and whatever else fancies our minds.
In conclusion, most Web APIs out there are just HTTP APIs, and that’s good enough. You can call them RESTful, I don’t even get mad anymore, simply because I don’t care, I’ll just check the docs to see how to use it. I’m more interested in providing value to people with interfaces they will like.
You will need to provide a human-readable documentation with your API, and it doesn’t matter if it’s RESTful, RESTish, RPC, or something else - and it’s all okay. Maybe one day, the gap will be bridged, but until then, we should worry about building things people want to use.
A good example to illustrate this point is the switch Github made, going from a RESTful API (with some pretty nice Hypermedia support) to using GraphQL, because following the REST principles was bloating their API and making it not flexible enough for its users.
I’m actually quite interested in using GraphQL and making clean RPC APIs lately, so I’ll probably cover those topics more in the future.
