
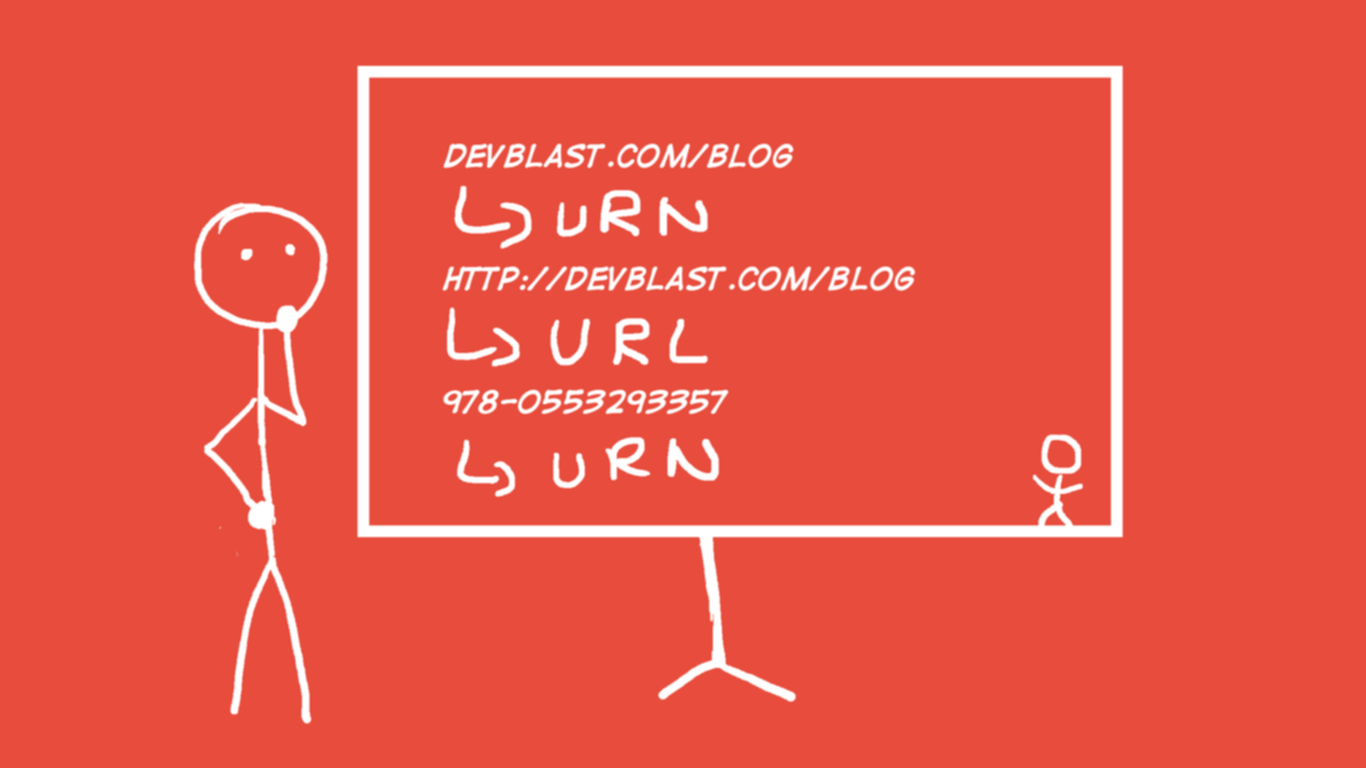
It is important to understand the difference between URLs, URIs, IRIs and URNs because they represent different concepts.
Tim Berners-Lee defined in RFC 3986 a “Uniform Resource Identifier (URI)” as “a compact sequence of characters that identifies an abstract or physical resource” and claimed that a “URI can be further classified as a locator, a name, or both.”
He also stated that the term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network ‘location’).
Got it?
Let me simplify this for you. Let’s say you are a resource -
- URLs are locators (hence the name). A URL is your home address: 12 Whatever Street, 11002, Paris.
- URNs are names. For you, a URN is your name: John Smith.
- URIs can be a locator (URL), a name (URN), or both.
Basically, all URLs are URIs, but not all URIs are URLs.
The only thing that can qualify a URI as a URL is if the latter includes how to find the former. www.google.com/account is not a URL, just a URI. However, http://www.google.com/account is a URL (and still a URI) because it includes the protocol (http://) that can be used to access the resource (www.google.com/account).
URNs are much simpler - they are just names.
An ISBN (like 978-0553293357) is a unique identifier for a book, which makes it a URI, and more specifically, a URN.
Finally, IRIs are an extension of URIs meant to include characters from the Universal Character Set (Japanese Kanji, for example). Indeed, URIs are limited to a subset of the ASCII character set.
I hope this little tip about the differences between those different acronyms help you to see clearer.
This is an extract from my book Master Ruby Web APIs.
